Malware 탐지 엔진
by Beom
<개요>
멜웨어 탐지 엔진은 최초 URL로 부터 정해진 Depth까지 웹을 크롤링하여 수집한 Resource, URL, Contents내에 있는 악성 코드, 악성 링크 등을 탐지하는 엔진.
<특징>
-
다중 모듈 구조로 컴파일이나 옵션 수정 없이 수집기와 분석기의 추가/삭제가 쉽다. (단순히 수집기나 분석기의 프로세스를 실행하거나 킬 하면된다.)
-
파일 기반의 큐를 사용하여 큐에 대기중인 데이터가 많아도 유실 없이 처리가 가능하다. 분석기와 수집기 사이의 의존성 없이 데이터를 처리 할 수 있다. (수집기가 수집한 데이터는 아무 분석기에서나 처리 되어도 상관없다.)
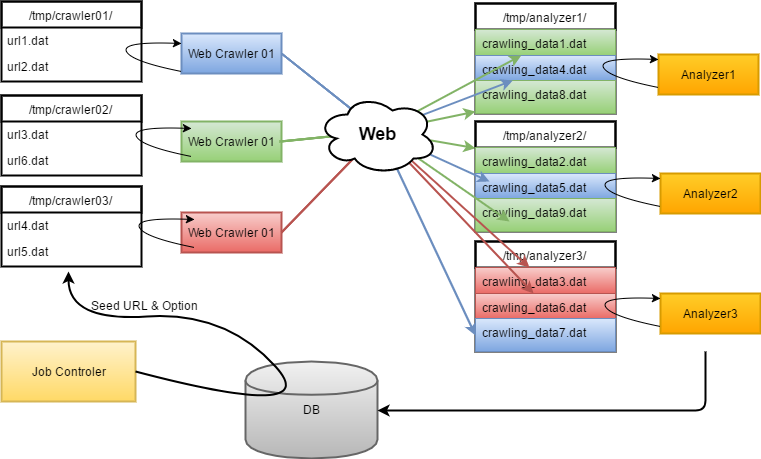
<시스템 구성="">
Job컨트롤러, 웹크롤러, 분석기, 파일 큐 로 구성 되어 있다. 크롤러는 각각 자신이 수집해야 할 URL의 정보가 저장 되어있는 파일 디렉터리를 가진다. 분석기는 각각 자신이 분석해야 할 크롤링 데이터가 저장 되어있는 파일 디렉터리를 가진다.
-
Job컨트롤러 :** DB로부터 분석 대상 도메인과 분석 옵션을 가져와 크롤러에 분배하는 작업을 한다. ++-선택 규칙 :++ 분석 대상은 URL마다 정해진 스케줄(주기, 시간)에 따라 선택 된다. ++-분배 규칙 :++ 선택된 URL은 수집 옵션(Depth, 외부 호스트 링크 등)과 함께 특정한 파일 형태로 만들어 크롤러 디렉터리에 저장한다. 이때 분배는 수집 대기중인 URL이 적은 크롤러 디렉터리에 우선 할당 한다.
-
Web 크롤러 : 자신의 데이터 디렉터리를 모티너링 하다 Job컨트롤러에 의해 새로운 URL 파일이 할당 되면 크롤링을 한다. 크롤러는 내부적으로 PhantomJS + CasperJS를 이용하여 수집한 데이터를 가공한다. 수집한 데이터는 분석기 디렉터리에 저장한다. ++-수집 규칙 :++ 최초 입력된 URL을 1Depth로 하여 지정된 Depth까지 모든 Page Contents,URL, Resource를 다운로드 받는다. ++-분배 규칙 :++ Job컨트롤러와 마찬가지로 수집 된 데이터를 특정 분석기에 할당 하는 것이 아니라 가장 여유가 많은 분석기 디렉터리에 할당한다.
-
분석기 : 자신의 데이터 디렉터리를 모니터링 하다 수집 완료된 url의 데이터를 분석한다.
< 수집기(크롤러) 아키텍쳐>
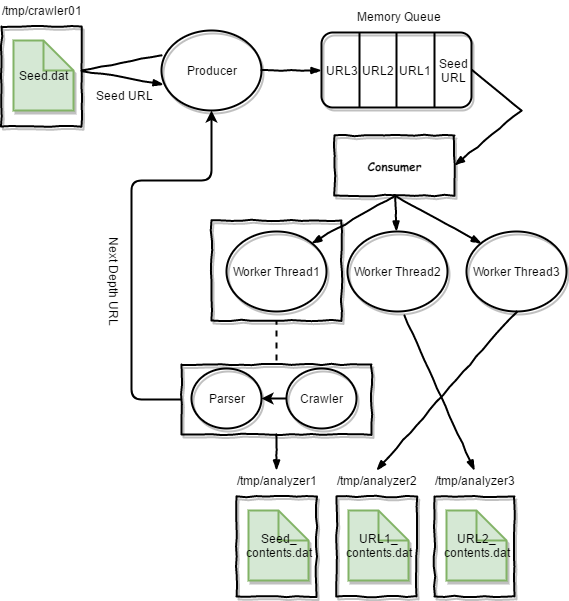
크롤러는 생산자/소비자 모델을 기본으로 구성 되어 있다. 프로듀서는 자신의 파일큐 디렉터리에서 Sedd_URL 정보를 받아 큐에 저장하고 기본적인 수집 옵션을 셋팅한다. 컨슈머는 최초 큐에 입력된 Seed URL을 크롤링 하여 수집한 리소스와 컨텐츠는 분석기 파일큐에 저장하고 Seed_URL로 부터 추출한 2Depth URL 링크를 프로듀서에 전달하여 저장한다. 컨슈머는 설정된 MaxDepth까지 계속 작업을 반복 한다. Work Thread는 파서와, 크롤링 스크립트 로 구성되며 크롤러는 PhantomJS + CasperJS를 이용하였다. 파서는 크롤링 스크립트가 수집한 데이터로 부터 ULR을 추출하고, 리소스등을 저장한다. Work Thread에서 수집한 데이터는 분석기 파일큐에 저장 되는데 이때 가장 한가한 분석기의 파일큐에 저장하도록 하여 각 분석기의 기아 상태를 예방한다. 2Depth부터 접근하는 URL들은 각각의 수집 속도가 다름으로 Seed URL에 설정된 Max Depth까지 모두 수집 될때 까지 기다릴 필요 없이 수집된 데이터는 즉시 분석하도록 분석 파일큐에 저장한다.
< 분석기 아키텍쳐>
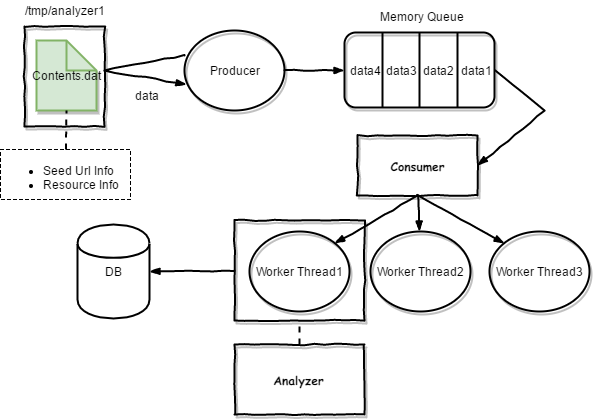
분석기는 기본적으로 생산자/소비자 모델로 구성 되어 있다. 프로듀서는 자신의 파일큐 디렉터리에서 크롤러가 수집한 데이터를 읽어 큐에 저장한다. 파일큐에 저장된 데이터는 Seed Url의 정보 현재 수집한 페이지의 정보 (url, depth), 다운로드한 리소스 정보등을 포함하고 있다. 컨슈머는 큐로부터 정보를 받아 분석 쓰레드를 생성하여 분석 작업이 이루어진다. 분석된 데이터의 결과는 DB에 저장되어 진다.
Subscribe via RSS
{kind=link}